Scraping EPL's Website¶
Most of the Premier League data on Kaggle looks rather sparse. Navigating to the results page on the English Premier League's website, we can see lists of every match for every season. Clicking on a match reveals lots of nice details such as the minute mark at which certain events such as goals occurred, along with a stats section displaying info such as the number of passes made for each team. I would like to scrape this data somehow.
Dealing with Dynamic Content¶
There are problems that need to be considered when scraping this particular website. This website dynamically generates content, which means that I may have to resort to using a browser automation tool such as Selenium that is capable of executing JavaScript. Before I resort to an approach like that which I assume will involve more configuration and coding, I will attempt to reverse engineer how the website is dynamically requesting content.
One problem that you will notice if you follow the link above is that when we request a season via the dropdown menu, there appears to be no clear pattern for the number of the request parameter se. This may be some kind of season ID, but how can we know which season it relates to without using the browser? By inspecting the dropdown element, I notice the following HTML:

The se request parameter appears to correspond to the data-option-id attribute, so I now have a means of requesting each season's match list page.
Another problem is that the pages for individual matches are requested dynamically via JavaScript. However, the pages for individual matches follow a pattern that use a match ID which can be extracted from the match container on the match list page. In the same way that I can request season match lists, I can also request pages for indivual matches.
On an individual match page, the content of the Stats tab is generated via JS. This case is more tricky because the content is updated using AJAX and the URL is not altered. Looking at the Network tab in Chrome's Dev Tools, I see that it is requesting data from some API.
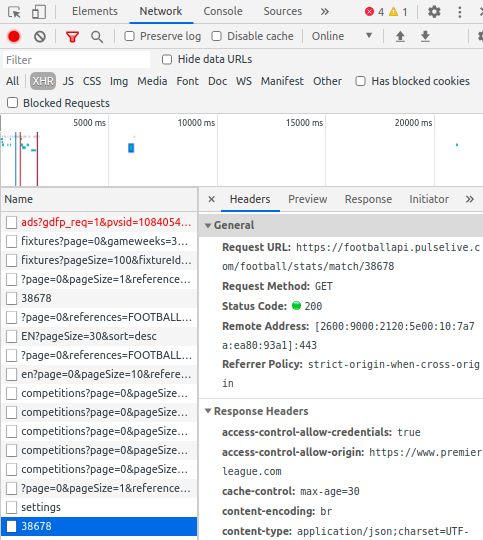
Requesting this URL outside of EPL's website results in a 403 Forbidden error. After doing some research, I discovered that this can be circumvented by setting the Origin header to EPL's domain. Sending the request using Postman gives me a JSON response with a bunch of data for the match. One problem that I notice is that an ID appears to be used for each team.
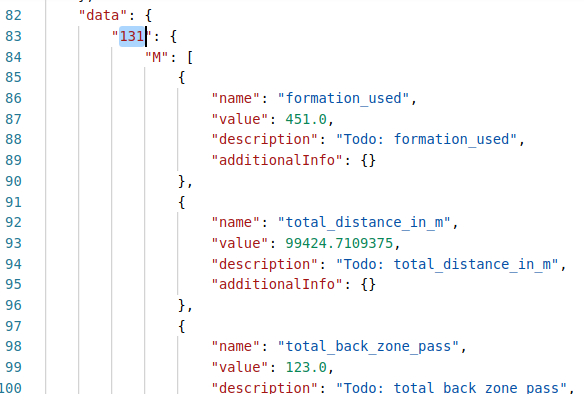
Looking back at the network tab in Dev Tools, I notice that other requests are being made to the same API. Requesting one of them gives me a JSON response containing team names and corresponding IDs.
One problem that I have overlooked is that the match lists for each season are also requested via AJAX. After spending too much time trying to figure out how this is done, I give up and decide to use a browser automation approach. I will use the Selenium API along with Chrome version 87 and its corresponding web driver. All is not lost; the information that I obtained above will likely still be of use.
Coding the Scraper¶
Here I begin to write my Scraper class and include a method to fetch the match IDs for a given season page. I am rendering all scraper-related code as non-executable markdown in this report. The script is named scraper.py. If you wish to run it yourself, you will need to have the web driver on your system's PATH.
